When a system becomes slow to change, unreliable, or hard to understand, the most tempting idea is:
“Let’s rebuild it properly.”
It sounds logical. Start fresh. Clean code. Modern stack. No legacy baggage.
For many SMEs, it’s also one of the highest-risk moves you can make.
This post explains why rewrites fail so often — and a safer alternative that modernises your system without putting the business on pause.
The rewrite promise (and why it’s attractive)
Rewrites are attractive because they promise:
- fewer bugs
- faster development
- modern architecture
- better performance
- happier engineers
And sometimes a rewrite is the right move.
But most SME rewrites don’t fail because the team is incompetent. They fail because the rewrite collides with how businesses actually work.
The real reason rewrites fail: the business keeps moving
A rewrite assumes you can “freeze” reality while the new system is built.
In an SME, you rarely can.
While the rewrite is happening:
- customer needs change
- regulations change
- competitors ship new features
- operations discover edge cases
- sales promises new workflows
- support learns where the real pain is
So the old system must keep evolving at the same time as the new one is being built.
That creates two expensive streams of work:
- Maintain the old system (because the business can’t stop)
- Build the new system (to replace it)
This is where timelines stretch, stress rises, and confidence drops.
The “Second System” problem (scope creep in disguise)
Rewrites often become a wish list:
- “Let’s do it properly this time.”
- “Let’s fix all the messy parts.”
- “Let’s add those features we never had time for.”
This is understandable — but dangerous.
It’s how rewrites turn into “build a perfect system” projects with:
- unclear scope boundaries
- delayed releases
- constant redesign
- endless debates about the ideal architecture
Even if the rewrite ships, it often ships late — and arrives missing the small operational details the old system accumulated over years.
The hidden complexity: legacy code contains business truth
Legacy systems feel messy, but they often encode real-world rules:
- billing exceptions
- customer-specific agreements
- regional differences
- workflow “quirks” that operations rely on
- edge cases discovered the hard way
A rewrite team usually underestimates this because much of that truth is undocumented.
So the new system becomes “clean” but incomplete.
And that’s when the business says:
“It doesn’t do what the old one did.”
The parallel-run tax: you pay twice for longer than you expect
To migrate safely, you often need a period where both systems exist:
- data must be migrated and reconciled
- integrations must be rebuilt
- reports must match
- teams must be retrained
- cutover plans must be rehearsed
This “dual running” phase is expensive and emotionally draining.
For SMEs, it’s common to reach a point where leadership asks:
“Why are we paying for two systems and still not finished?”
When rewrites can be justified
Rewrites are sometimes appropriate when:
- the current system is fundamentally unmaintainable (e.g., no deploy path, unsupported runtime, severe security issues)
- the domain is stable and well understood (requirements aren’t changing weekly)
- you can deliver in slices (not one big launch)
- you have strong technical leadership and test discipline
- there is a clear migration plan with measurable milestones
If those conditions aren’t true, a rewrite is usually a bet with poor odds.
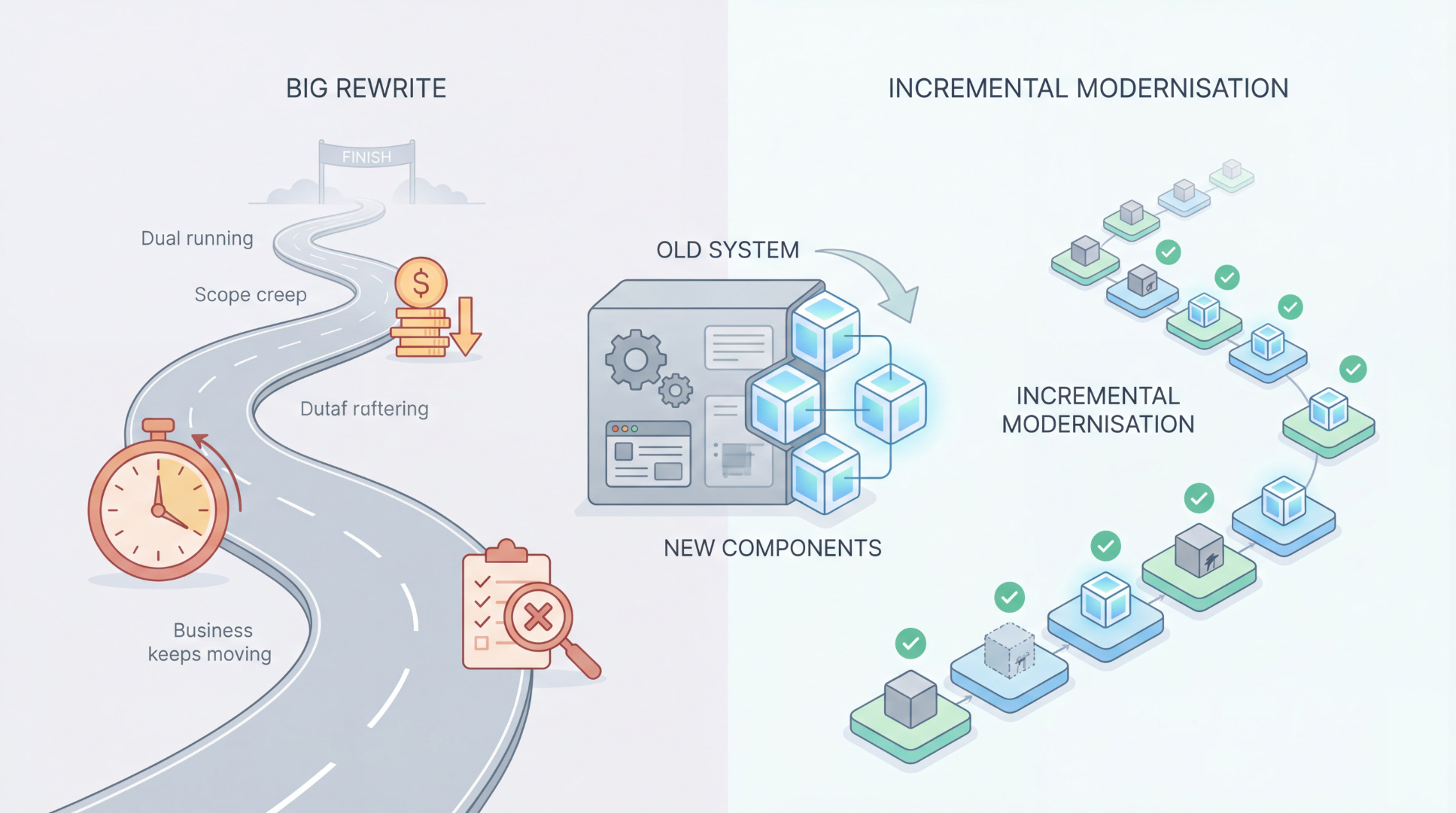
The safer alternative: modernise incrementally (without stopping the business)
Instead of “replace everything,” aim for: reduce risk + increase change capacity step by step.
A proven approach looks like this:
1) Stabilise the system first
Before big change, reduce uncertainty:
- improve monitoring and logging
- make deployments safer (rollback plan, smaller releases)
- add tests around critical behaviour (even if the code is messy)
This is the “freeze” step: lock in today’s behaviour so you can improve it safely.
2) Pick one thin slice with clear business value
Examples:
- notifications
- reporting
- search
- a specific checkout step
- an internal admin workflow
Deliver a small win that reduces risk or improves revenue — and proves the method.
3) Use the “strangler” approach
Build new functionality around the old system and gradually move responsibility:
- route certain requests to the new component
- keep old behaviour as a fallback
- expand coverage over time
This avoids the big-bang cutover that causes most disasters.
4) Repeat with confidence
Each iteration improves:
- system boundaries
- test coverage
- observability
- deployment safety
- team speed
Over time, the “old system” shrinks, and the business keeps moving.
A CEO checklist: how to spot a risky rewrite proposal
If someone proposes a rewrite, ask:
What business outcome do we get in the first 30–60 days? If the answer is “nothing until the big launch,” risk is high.
How will we prevent missing legacy behaviour? If there’s no test strategy, you’re guessing.
How will we migrate data safely and prove correctness? If the plan is vague, expect delays.
What’s the rollback plan if cutover fails? If there isn’t one, the cutover will be stressful and dangerous.
Can we deliver in slices instead of one big replacement? If not, reconsider.
The takeaway
Rewrites fail because they assume the business can stop changing while software is rebuilt.
For SMEs, the safer and more effective strategy is usually:
- stabilise first
- modernise in small slices
- reduce risk
- expand the modernised surface area over time
The goal isn’t a “perfect” system. The goal is a system you can change safely — while the business continues to grow.